Daniel Alonso, AI assistance disclosed. May 8, 2026.
A forced-choice audit of 42 LLMs across 50,400 planned trials and 48,316 successful one-word responses. The study measures behavioral regularities in arbitrary binary choices, not belief, intent, or consciousness.
OK rows48,316
First-option share60.4%
Exact parses99.5%
SpendUSD 28.60
Top word-level preferences after combining bare and swapped prompts: sweet 90.6% over bitter; smooth 88.3% over rough; quiet 87.1% over loud; fast 86.5% over slow.
Setup
The run used 30 word pairs, 60 context snippets, normal and swapped order controls, ten repetitions, and temperature 0.7. Calls went through OpenRouter as the study API and spend platform, then landed in SQLite with raw responses, parser decisions, usage rows, and attempt history.
The practical point is narrow: if product logic asks a model to choose between arbitrary labels, the answer should not be treated as a neutral random draw unless the workflow measures and controls for order, wording, and context.
Prompt Design
Bare prompts used the template Choose one: first or second. Reply with exactly one word. Context prompts prepended one weak sentence to the same choice. Normal and swapped orders were both collected.
Prompt condition design.
Condition
Order
Context
Shape
OK / planned
bare
original order
no
bare template
12,081 / 12,600
bare swapped
swapped order
no
bare template
12,072 / 12,600
context
original order
yes
context sentence + bare template
12,074 / 12,600
context swapped
swapped order
yes
context sentence + bare template
12,089 / 12,600
Model Coverage
The pool covered 42 models across 22 providers and 21 model families. Provider, family, and tier labels are descriptive route metadata, not rankings.
Model coverage by tier.
Tier
Description
Models
OK rate
Mean first
Mean semantic
flagship
flagship / frontier-class
10
99.6%
60.4%
56.7%
mid
current mid-tier
10
100.0%
57.8%
49.9%
open
open-weight or open-route
5
100.0%
62.2%
41.1%
small
small or fast tier
16
89.4%
61.0%
49.4%
unknown
uncategorized
1
99.9%
63.3%
49.0%
Model coverage by provider.
Provider
Models
OK / planned
OK rate
Mean first
Status mix
Alibaba/Qwen
3
3,580 / 3,600
99.4%
57.9%
error 18; ok 3,580; rate limited 2
Amazon
1
1,200 / 1,200
100.0%
57.1%
ok 1,200
Anthropic
3
3,600 / 3,600
100.0%
61.8%
ok 3,600
Baidu
2
1,200 / 2,400
50.0%
52.1%
error 34; model removed 444; ok 1,200; rate limited 722
DeepSeek
3
3,599 / 3,600
100.0%
61.6%
error 1; ok 3,599
Google
3
3,599 / 3,600
100.0%
53.6%
error 1; ok 3,599
IBM Granite
1
1,200 / 1,200
100.0%
65.8%
ok 1,200
Inception Labs
1
1,200 / 1,200
100.0%
67.5%
ok 1,200
Liquid AI
1
1,198 / 1,200
99.8%
82.4%
error 2; ok 1,198
Meta
3
3,598 / 3,600
99.9%
65.2%
error 2; ok 3,598
Microsoft
1
1,198 / 1,200
99.8%
48.6%
error 2; ok 1,198
MiniMax
3
3,598 / 3,600
99.9%
66.9%
error 2; ok 3,598
Mistral AI
2
2,400 / 2,400
100.0%
64.5%
ok 2,400
NVIDIA
2
2,400 / 2,400
100.0%
65.2%
ok 2,400
Nous Research
2
2,400 / 2,400
100.0%
50.5%
ok 2,400
OpenAI
2
2,400 / 2,400
100.0%
48.0%
ok 2,400
Perplexity
1
1,199 / 1,200
99.9%
49.1%
error 1; ok 1,199
Reka AI
1
382 / 1,200
31.8%
51.0%
invalid 126; model removed 692; ok 382
Tencent
1
1,196 / 1,200
99.7%
74.6%
error 4; ok 1,196
Z.ai
3
3,599 / 3,600
100.0%
56.8%
error 1; ok 3,599
tencent
1
1,199 / 1,200
99.9%
63.3%
error 1; ok 1,199
xAI
2
2,371 / 2,400
98.8%
65.8%
error 29; ok 2,371
Model coverage by family.
Family
Models
Providers
Tiers
Mean semantic
Claude
3
Anthropic
flagship, mid, small
54.1%
DeepSeek
3
DeepSeek
flagship, mid, small
48.0%
GLM
3
Z.ai
mid, small
65.2%
Gemini
3
Google
flagship, small
76.9%
Llama
3
Meta
open
36.6%
MiniMax
3
MiniMax
flagship
38.6%
Qwen
3
Alibaba/Qwen
flagship, mid, small
67.1%
ERNIE
2
Baidu
small
64.3%
GPT / OpenAI
2
OpenAI
mid, small
45.5%
Grok
2
xAI
flagship, mid
39.1%
Hermes
2
Nous Research
flagship, open
61.0%
Hunyuan
2
Tencent, tencent
small, unknown
36.0%
Mistral
2
Mistral AI
mid, small
38.8%
Nemotron
2
NVIDIA
open, small
47.0%
Granite
1
IBM Granite
small
48.3%
LFM
1
Liquid AI
small
5.5%
Mercury
1
Inception Labs
mid
50.3%
Nova
1
Amazon
flagship
47.7%
Phi
1
Microsoft
small
60.2%
Reka
1
Reka AI
small
39.4%
Sonar
1
Perplexity
mid
50.3%
Word-Pair Design
The word set used short, ordinary labels instead of factual questions. The context labels are hypotheses, which is why backfires are reported separately.
Word-pair categories.
Category
Pairs
Pair labels
abstract
2
narrow/wide; simple/complex
color
3
blue/red; green/purple; yellow/gray
density
1
light/heavy
direction
2
left/right; up/down
material
2
glass/stone; wood/metal
motion
1
fast/slow
nature
1
river/forest
object
3
candle/lamp; cup/plate; key/coin
shape
2
circle/square; triangle/oval
size
1
small/large
sound
2
loud/quiet; sharp/mellow
taste
2
salty/sour; sweet/bitter
temperature
1
warm/cold
terrain
1
mountain/valley
texture
2
smooth/rough; soft/hard
time
2
early/late; morning/evening
weather
2
humid/dry; windy/still
Condition Summary
Completion and first-position share by prompt condition.
Condition
OK / planned
OK rate
First-option share
bare
12,081 / 12,600
95.9%
75.8%
bare swapped
12,072 / 12,600
95.8%
59.3%
context
12,074 / 12,600
95.8%
51.1%
context swapped
12,089 / 12,600
95.9%
55.5%
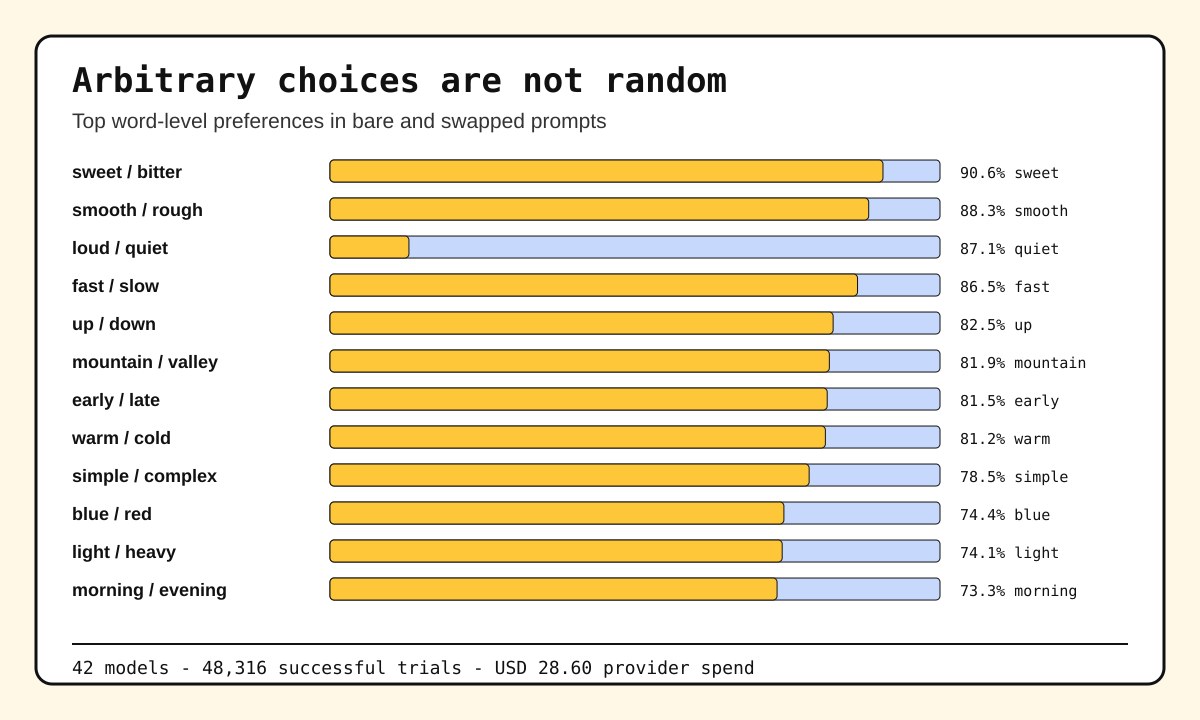
Strongest Word Preferences
Strongest aggregate word preferences after combining bare and swapped prompts.
Pair
Majority option
Majority share
sweet / bitter
sweet
90.6%
smooth / rough
smooth
88.3%
loud / quiet
quiet
87.1%
fast / slow
fast
86.5%
up / down
up
82.5%
mountain / valley
mountain
81.9%
early / late
early
81.5%
warm / cold
warm
81.2%
simple / complex
simple
78.5%
blue / red
blue
74.4%
Strongest Position Skews
Models with the strongest first-displayed-option skew.
Model
Provider
First share
Semantic strength
LFM2-24B-A2B
Liquid AI
82.4%
5.5%
Hunyuan A13B Instruct
Tencent
74.6%
23.0%
Llama 3.3 70B Instruct
Meta
71.8%
15.3%
MiniMax M2.7
MiniMax
69.4%
35.7%
Mercury 2
Inception Labs
67.5%
50.3%
Mistral Medium 3.5
Mistral AI
67.2%
35.7%
Nemotron 3 Nano 30B A3B
NVIDIA
67.2%
41.3%
Claude Sonnet 4.6
Anthropic
67.1%
33.0%
Grok 4.3
xAI
66.5%
40.5%
DeepSeek V4 Flash
DeepSeek
66.4%
40.7%
Largest Context Lifts
Largest mean context lifts toward the inferred associated option.
Context
Target
Mean lift
ctx_black_coffee
bitter
89.2 pp
ctx_old_rope
rough
87.8 pp
ctx_concert_line
loud
86.9 pp
ctx_old_turtle
slow
85.6 pp
ctx_stairs_basement
down
77.8 pp
ctx_suitcase
heavy
74.1 pp
ctx_sunset_walk
red
73.3 pp
ctx_corridor
narrow
72.7 pp
ctx_dinner_lights
evening
72.3 pp
ctx_machine_diagram
complex
68.0 pp
Context Backfires
Not every human-written cue behaved as intended. These rows moved away from the inferred target, which is useful evidence that weak contextual labels are not self-validating.
Context cues that moved away from their inferred target.
Context
Target
Mean lift
Text
ctx_bakery_case
sweet
-51.7 pp
The bakery case was almost empty by the time the queue moved.
ctx_alarm_clock
morning
-25.4 pp
The alarm was set before the bag was packed.
ctx_race_start
fast
-16.4 pp
The runners waited for the signal at the start line.
ctx_morning_window
yellow
-9.0 pp
The room was quiet when light first came through the window.
Data Quality and Accounting
48,091 of 48,316 OK rows were exact parses. Final status rows, parser rows, usage rows, and retry caps are retained so operational problems remain visible.
Final trial and parser status.
Trial status
Rows
Parser status
Rows
error
98
exact
48,091
invalid
126
none
1,266
model removed
1,136
invalid
818
ok
48,316
single token in text
118
rate limited
724
repeated single option
106
manual override
1
Cost and token accounting.
Metric
Value
Note
OpenRouter dashboard spend
USD 28.60
External dashboard total used as the public spend figure.
Trial usage rows
USD 20.78
Usage JSON attached to final trial rows.
Attempt usage rows
USD 22.21
Captured provider attempts, including retries after attempt logging was added.
Prompt tokens
2,270,506
Captured attempt-level prompt tokens.
Completion tokens
10,908,206
Captured visible plus provider-reported completion tokens.
Reasoning tokens
10,471,809
Provider-reported hidden reasoning tokens when present in usage details.
Operational Concentration
96.8% of non-OK rows came from the two preserved caveat models. Reka Flash 3 alone accounts for 36.2% of captured completion tokens despite only 382 OK rows.
Where non-OK rows concentrated operationally.
Model
Provider
Non-OK rows
Share of all non-OK
ERNIE 4.5 21B A3B
Baidu
1,200
57.6%
Reka Flash 3
Reka AI
818
39.2%
Grok 4.3
xAI
29
1.4%
Qwen3.6 Max Preview
Alibaba/Qwen
20
1.0%
Attempt Retry Envelope
Recorded attempts are grouped by their captured max_tokens setting so final trial status is not the only operational signal. The high-token rows show why retry behavior is treated as a caveat instead of being folded into model preference results.
Recorded attempts grouped by max_tokens retry cap.
Token cap
Recorded attempts
OK attempts
Non-OK mix
0
1
1
none
512
49,956
46,964
invalid 2,173; error 95; rate limited 724
3,000
1,262
465
invalid 797
20,000
1,043
886
invalid 154; error 3
Caveats
ERNIE 4.5 21B A3B and Reka Flash 3 were preserved as operational caveats. One ERNIE 4.5 300B A47B row was manually overridden with an audit trail. Dashboard spend was about USD 28.60; recorded attempt usage sums to USD 22.21 because early superseded attempts were not all captured.
Limitations
The task is intentionally narrow: ordinary binary word choices, not factual QA, planning, tool use, safety behavior, or human preference modeling.
The measured quantities are behavioral regularities in one-word responses. They are not evidence of belief, intent, consciousness, moral preference, or stable model personality.
OpenRouter provider routing was not pinned: calls used the bare model field with no provider.order or provider.only constraints, so a single nominal model id was free to be served by any of OpenRouter's available backends within the run. Closed-source models effectively hit one backend each, but open-weight routes hit many in the same run (DeepSeek v3.2: 9 providers; Llama 3.3 70B: 13; DeepSeek v4 Pro: 6). The first-option rate within one open-weight model varies up to roughly 8 percentage points across its serving providers, so per-model rankings on open-weight routes carry routing noise on top of the model itself. The served provider is recorded per attempt for slicing.
Default decoding behavior and hidden reasoning are part of the observed run. Different reasoning controls or temperatures could change the measurements.
Per-cell statistical power is small: 10 reps per (model, pair, condition) gives a binomial 95% CI half-width of about ±15 pp at p=0.5. Aggregate findings (overall position bias across 48 k rows, per-model first-option share across 1,200 rows, per-pair preference across ~800 rows) are statistically robust; single (model, pair, condition) cell claims should be treated as exploratory.
Per-pair preferences are not just unigram corpus frequency. Regressing the order-balanced option-A share on the wordfreq Zipf log-frequency gap across the 30 pairs gives Pearson r = 0.235, R-squared = 0.055, slope p = 0.21; the more frequent token wins only 19 of 30 pairs. Clear counter-frequency cases include sharp/mellow (mellow wins 70% despite a 1.16-Zipf gap toward sharp), smooth/rough, warm/cold, and circle/square. This rules out the simplest unigram-frequency confound but does not rule out richer frequency-based stories such as collocation strength or one-word answer typicality.
Context labels are researcher hypotheses inferred from weak wording. Reverse context rows are reported because the cues are not ground-truth semantic interventions.
96.8% of non-OK rows came from two caveat routes, so reliability conclusions should focus on the preserved status counts rather than average all-model failure behavior.
Attempt-level cost accounting is incomplete for early superseded retries because full attempt logging was added during the run; the dashboard spend is therefore retained as the headline spend figure.
Data Availability
The public machine-readable release in this web package is study-summary.json, with a JSON Schema and artifact manifest that expose record counts, field names, metric definitions, byte sizes, and SHA-256 hashes. The study code is published in the linked GitHub repository. The public summary includes model rows, provider rollups, pair bias rows, per-model pair bias rows, context effects, status counts, parse counts, attempt-token groups, cost fields, caveats, a data dictionary, and metric definitions.

{kind=link}
{kind=link}